
你好,我叫正在Cross Language这个公司开发规则库机器翻译以及nyuraru机器翻译系统的机器翻译引擎的nyama。作为开发机器翻译的技术员,最近关于注目度高的机器翻译随着AI的进化介绍那套结构。
在开始

AI(人工智能)被dipuraningu(Deep Learning:深层学习)的出场认为进入了第3次热潮,是图像识别,语音识别以及机器翻译含有的自然语言处理各种各样的领域,并且AI变得积极活动了。发表Google把dipuraningu用于在2016年9月的nyuraru机器翻译服务,那个机器翻译的翻译精度戏剧性地提高的变成了大的话题。
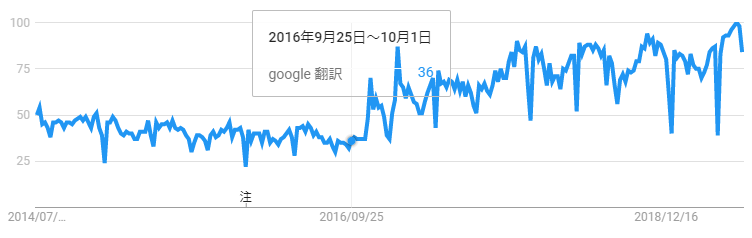
知道从Google倾向,"Google翻译"这个关键词也被搜索的件数2016年9月以后在增加。以及nyuraru机器翻译从这个时机起在机器翻译的领域一口气开始扩大了。
原来机器翻译的历史旧,并且机器翻译专利被在1933年俄国人技术人员申请。那之后,机器翻译的手法估计阶段①规则库机器翻译(Rule Base Machine Translation,俗称RBMT),②统计上的机器翻译(Statistical Machine Translation,俗称SMT),③nyuraru机器翻译(Neural Machine Translation,俗称NMT),进化了。
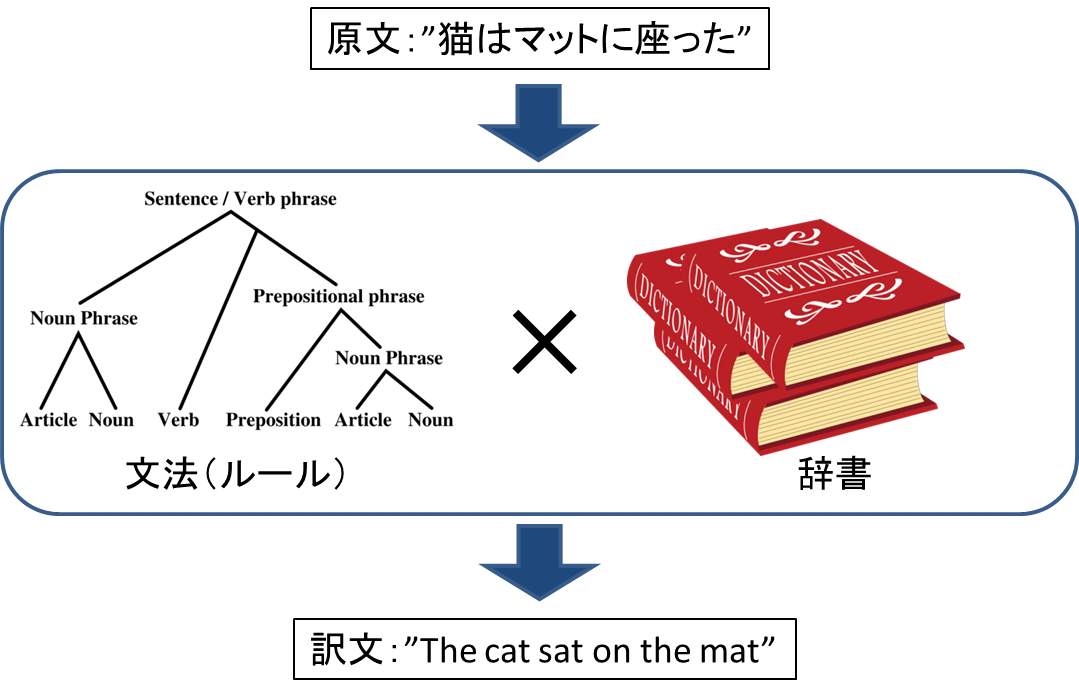
① 规则库机器翻译(RBMT)
RBMT被从几十年前开发,历史作为机器翻译的手法最长。因为乔治城大学的研究小组在1954年发表机器翻译系统了所以词素分析或者依存分析等的RBMT需要的技术的研究开始了。用一句话表现RBMT的手法的话是一边比较人类事先做的语法规则和词典信息,一边形成译文的东西。为此,高度的语言知识被向开发者寻求,为翻译精度提高有巨大的人手的作业时间。
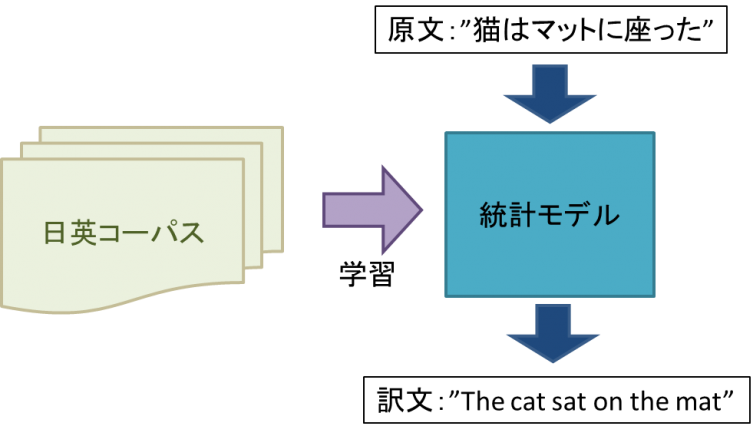
② 统计上的机器翻译(SMT)
建议让IBM方面在在1990年代不同的语言之间的单词对统计而言支持的"IBM型号"这个手法这个SMT的开始了。用SMT,作为学习数据给与被叫做"语言资料库"的大量的直译数据(对原文数据和人类把那个翻译成的译文数据的东西的数据),让计算机学习统计模型。以及让使用那个统计模型,形成译文。为包括在1单词的前后的单词在内翻译组合的概率高的东西被作为译文形成。必须让准备大量的语言资料库,模特学习,但是如果有语言资料库和学习程序的话,为计算机进行人手不患学习本来。
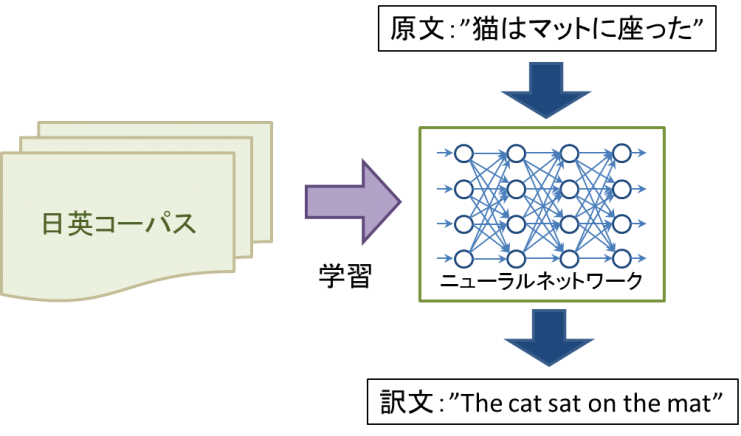
③ nyuraru机器翻译(NMT)
用nyuraru机器翻译(NMT),正应用于使dipuraningu神经网。模拟在脑功能认为是神经网的若干的特殊性的数理性的被在型号在1957年设计的感知器用那个开端做。在dipuraningu前面的神经网,有陷入斜面消失以及局部最合适的解的问题,没能充分学习。但是,多层神经网(Deep Neural Network)的研究繁盛,并且变得被进行计算机的性能增强和出自Web发达的学习数据提供的容易化了。
使用dipuraningu的应用程序在1990年代在语音识别的领域最初登场,关于机器翻译的神经网的使用的第一次的学术论文被在2014年发表了。用SMT,重新排列,存在型号这样的复数的型号语言模型,翻译型号,但是,在NMT,只一个结束二结束(end-to-end)型号被学习。在NMT,因为能作为文脉管理全体句子的信息所以语序以及结构到达高的翻译精度在不同的语言间隔也。另外,因为在人类翻译的文章的基础上学习所以也学习译文的特征,成为在近的自然的文章对人类也写被形成的译文的东西。为,但是,NMT的翻译精度依赖神经网的基本结构(计算型号)和学习数据可能在根据学习数据的量以及质量错的翻译结果输出。
各手法的比较
| RBMT | SMT | NMT | |
| 译文的特征 | ・对口语的对应困难 ・译文的表达牢固变得可能不自然 |
能抽出单词以及词组之间的关系,但是可能有是长句的话不能巧妙抽出全体句子的结构的事情 | ・变成自然的文章 ・訳抜keya訳過多可能发生 |
| 未知的词对应 | 0 (能用词典登录对应) |
△ (语言资料库补充和再学习需要) |
△ (语言资料库补充和再学习需要) |
| 訳抜keya訳過多 | 0 | 0 | ✕ |
| 语言资料库量 | 0 | △ (大量需要) |
△ (大量需要) |
| 计算量 | 0 | △ | △ |
| 开发成本 | ✕ | 0 | 0 |
| 对多语言的对应 | ✕ (开发每隔语言需要) |
0 (如果有语言资料库的话,只用学习能展开) |
0 (如果有语言资料库的话,只用学习能展开) |
| 翻译精度 | △ | △ | 0 |
| 翻译过程的控制 | 0 | ✕ | ✕ |
像这样,在各手法分别有优点和缺点。NMT由于流畅形成自然的译文,但是有没正精确地翻译原文全部可能性。关于专有名词或者数字等的正确特别被要求的东西,需要警告。比方说大阪地铁"堺筋线"的翻译结果和"Sakai Muscle line"在使用某一个NMT方式的机器翻译系统的Web网站误译的变成了新闻。这种误译,和原因在学习数据可以考虑从"堺筋线"有许多"堺","条纹","线"分别的单汉字的数据量,事情。甚至人类就是关于甚至机器学习没与读初次看的汉字难的同样地学习过的单词以及文章确实翻译成难。
为修改这种误译在SMT,NMT新追加学习数据,必须再一次学习翻译型号。顺便,在RBMT,登记能对词典解决单词。
用机器翻译,不理解语言的意思

不到单词的意思在学习单词之间的前后关系以及直译关系的东西学习机器翻译的学习。比方说仅仅只是听"苹果"这个单词也人类想像实物的苹果,苹果,颜色或者形状等的苹果的各种各样的特征作为食物的以及那个味道又浮在上面。人类,結bizukete学习在用五感体验的事情以及自己的行动语言。另一方面从出现在语言资料库关于"苹果"这个单词的"味道好的苹果"以及"吃苹果"的文章在机器学习只学习与其他的单词以及词组的关系以及"苹果→apple"这个直译关系。在翻译的时候理解句子的意思之后人类的翻译家用其他的语言表现那个。但是,在与其他的单词的关系以及直译关系的基础上像前述那样用机器翻译翻译。为此,用现在的机器翻译,不能期待着全然和人类一样的水准的翻译结果。
翻译的用途
机器翻译100%正确,并且RBMT,SMT,NMT哪一方面不能把所有的句子翻译成。为此,必须根据需要分别使用。比方说在为了由于流畅一定程度上意思清楚想翻译句子以及文章的内容的时候,是NMT,正确重要的专有名词或者数字加入了的文章,并且使用RBMT,在被两个都要求的时候依赖人类的翻译家,翻译家检查机器翻译的结果的用途、组合最好。另外,在使用机器翻译的时候在没有简洁,暧昧的表达的日语(在从日语到外语翻译的时候)有误译于是减少的倾向的知道原文。
本公司的行动
在本公司,正跟RBMT和NMT的两者进行开发以及研究。最近,根据RBMT在新元号"令和"被发表的当天善于的"规则的建设,"和"2018年"的翻译对应了。请一定用本公司经营的免费的翻译网站CROSS-Transer试。![]()